What are the typical stages of applying statistics in a Lean Six Sigma project?
Statistical application typically begins with data classification and representation, moves to descriptive statistics to summarize current performance, advances to inferential techniques for estimation and hypothesis testing, and concludes with defining performance measures and variation analysis as reflected in sections on data classification, descriptive and inferential statistics, and performance measures.
How do confidence intervals support decision-making in process improvement?
Confidence intervals quantify the range within which a population parameter likely falls based on sample data, helping teams assess uncertainty around estimates and support decisions about process changes; the presentation covers calculating confidence intervals alongside hypothesis testing as part of inferential statistics.
Which summary statistics are most useful for understanding process data distributions?
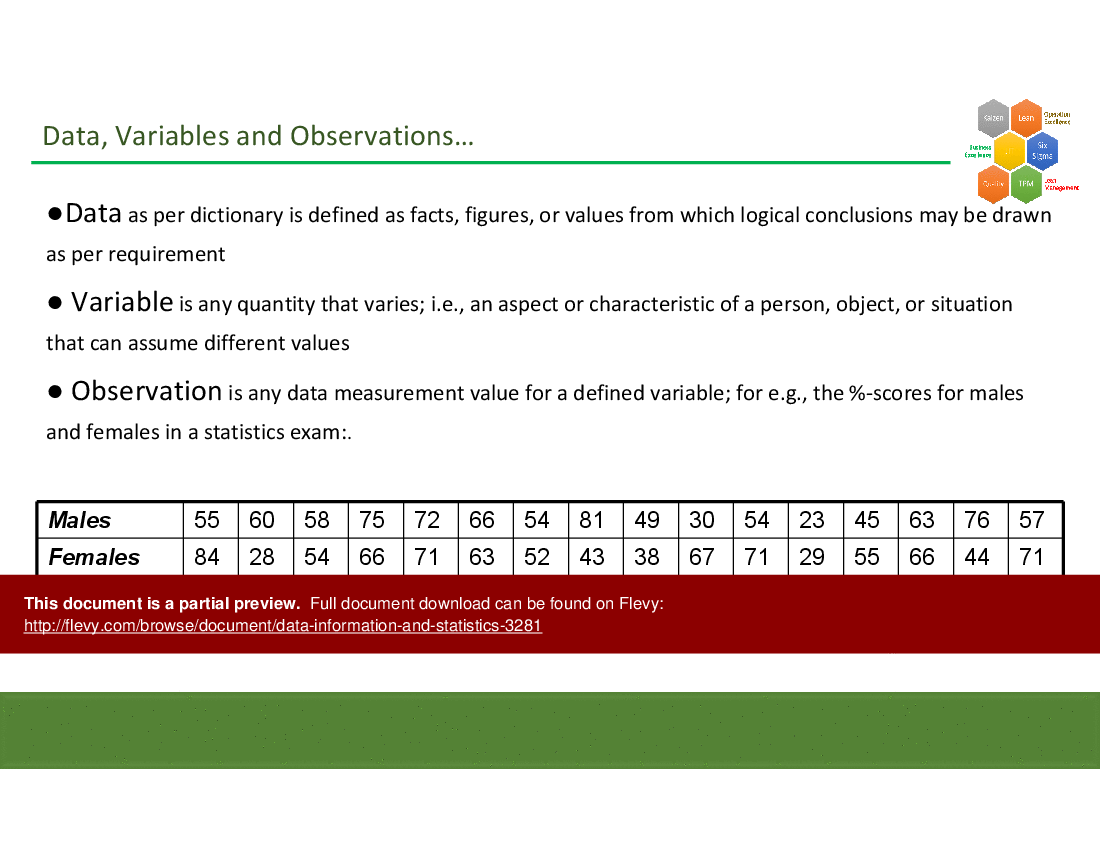
Measures of central tendency (mean, median, mode) and measures of dispersion (standard deviation, variance) are commonly used to summarize process data and understand spread; these descriptive statistics are explained with examples and worksheets in the deck.
How should I distinguish common cause and special cause variation when diagnosing a process?
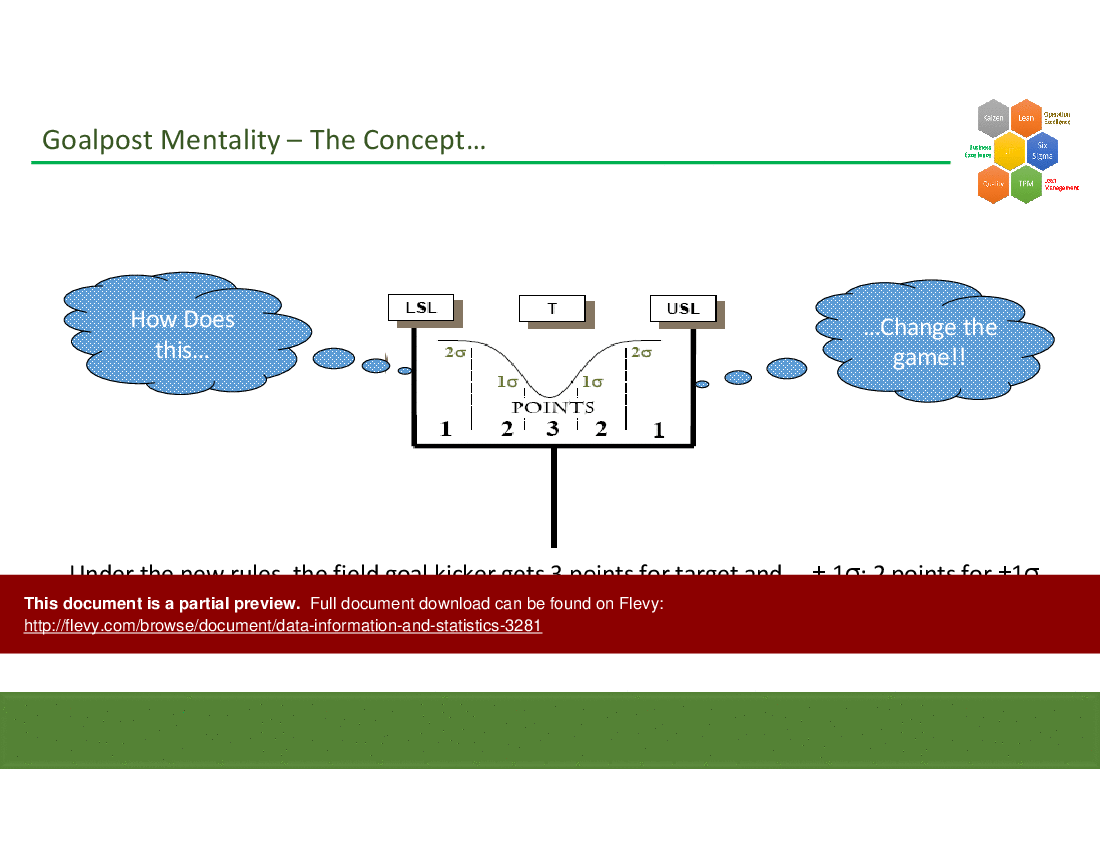
Common cause variation is inherent, predictable variation within a process, while special cause variation stems from external or assignable events; distinguishing them is central to variation analysis and is addressed alongside the variation-vs-goalpost concept in the material.
What features should I expect in a statistical training deck for Yellow/Green Belt programs?
Look for clear modules on data classification and representation, worked examples of descriptive statistics, inferential models for confidence intervals and hypothesis testing, graphical tools for visualization, and templates or checklists to support exercises—such as data classification templates and descriptive statistics worksheets found in Flevy's Data, Information, & Statistics.
Are prebuilt statistical templates cost-effective for internal training and workshops?
Prebuilt templates reduce preparation time and provide consistent structure for exercises and operational definitions; the author notes the presentation can be customized for internal training and is suitable for Yellow and Green Belt programs, making it adaptable for organizational use.
How do I choose the right chart type for different data types during analysis?
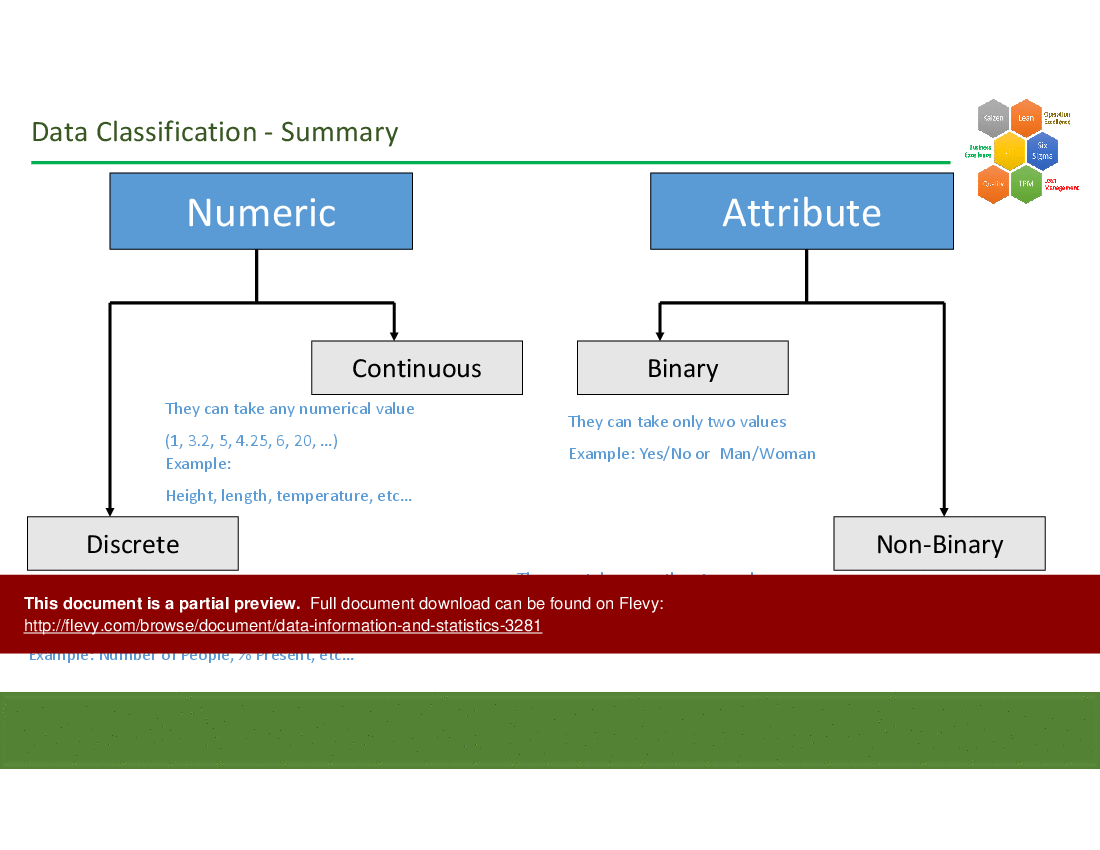
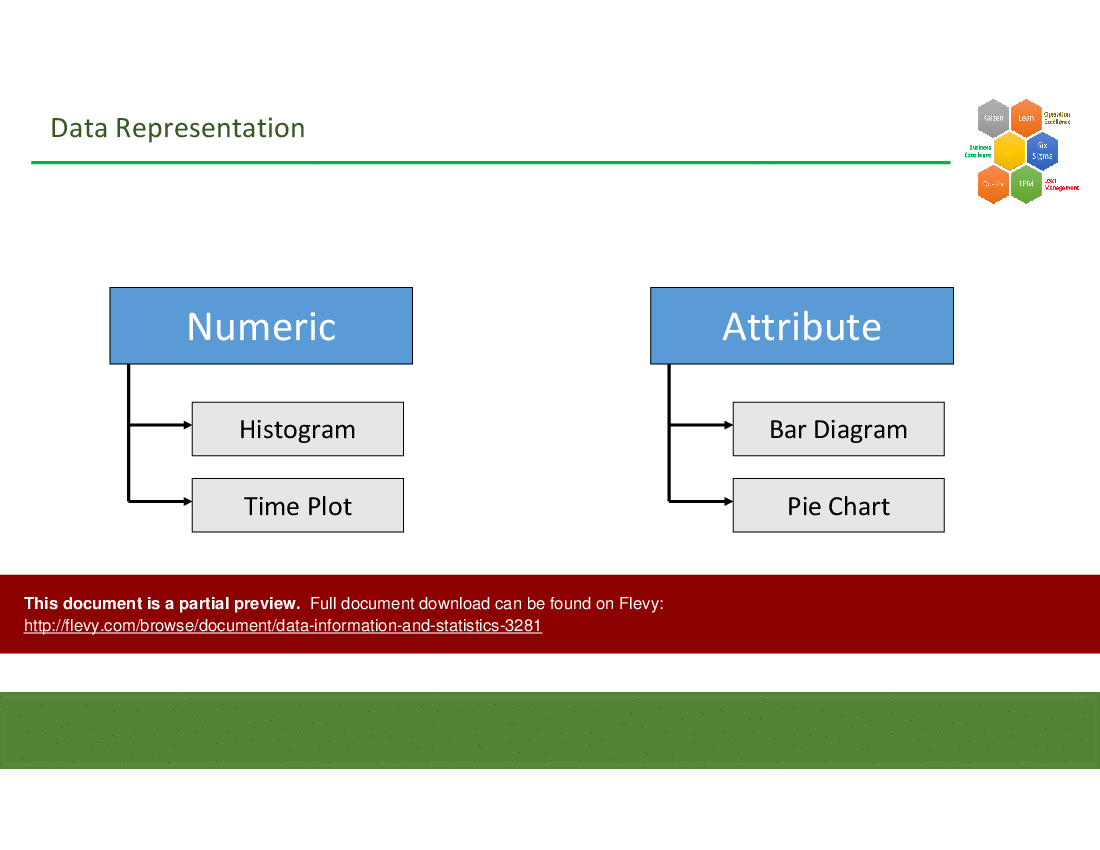
Classify data first as numeric (continuous or discrete) or attribute (categorical); use histograms for numerical distributions and pie charts for categorical breakdowns, as illustrated in the deck's sections on data representation with examples of histograms and pie charts.
How can I structure a workshop focused on inferential statistics for operations teams?
Use a session sequence that introduces data and classification, follows with a focused Descriptive and Inferential Statistics block featuring hands-on confidence interval and hypothesis testing exercises, and ends with performance-measure application; the deck includes a suggested agenda with a 90-minute Descriptive and Inferential Statistics session that includes confidence interval exercises.